

SimArena: A reinforcement learning arena for training autonomous Kubernetes AI agents

Happy June, everybody! In this post, we’re going to take a quick detour from our strategic plan to do a recap of the second clinic project that ACRL has sponsored with Harvey Mudd College (HMC). Just as a quick reminder, one of ACRL’s goals is to promote and facilitate public, open-source research and development, and the HMC clinic program is a really fantastic way to facilitate this. At HMC, every graduating senior has a requirement to participate in either a thesis project (which is a 1-1 guided research project with a faculty advisor, very similar to the experience you might get in graduate school), or a clinic project, where a team of seniors work together with a faculty advisor and sponsoring company on a project of interest to the sponsor.
Both projects that ACRL has sponsored have been SimKube-related (of course); last year’s project tackled a data-generation project, specifically trying to address the question of “How can we bootstrap a small amount of SimKube trace data into a large amount of data?” One potential use case for this would be as training data for an autonomous Kubernetes AI agent. This year’s project tackled a complementary question, namely: “Given that we have a whole bunch of training data, how can we actually build an interface or environment for an agent to learn from it?”
Answers to both of these questions are necessary (but probably not sufficient!) for developing some machine learning model that can actually operate (or even diagnose!) complex distributed systems like Kubernetes.
The training arena theory
In the AI/ML space, there are lots of “arenas” or “gymnasiums” that people use as a sandbox for agents to perform learning and evaluation tasks. The idea is that you provide your reinforcement learning (RL) agent a carefully-controlled environment and a goal, and through many, many training iterations, the agent eventually learns how to accomplish the goal; and if you’re exceptionally lucky, maybe it can also generalize what it learns. There are a number of popular arenas for various video games, including MineDojo for MineCraft and MiniHack for NetHack1.
And, since obviously Kubernetes is just a giant video game, this concept translates naturally.
So this was the project that I tasked the clinic team with: use SimKube to build a training arena for Kubernetes RL. Just like year, this was a very open-ended “research-oriented” project; there aren’t any right answers, and I was very up-front with the team that if we got to the end of the project and the outcome was “this is a dumb idea and here’s why,” that would have been a success in my book.
Fortunately that’s not what happened!
To go big, you gotta start small
Distributed systems generally (and Kubernetes specifically) are enormously complex2, and it turns out that machine learning isn’t easy either3. I was able to provide a lot of expertise and guidance on Kubernetes and distributed systems, but I do not have the ML expertise that was needed for this project4; fortunately, the faculty advisor that we were working with is an expert in reinforcement learning and machine learning, and was able to provide the needed expertise for this side of the project.
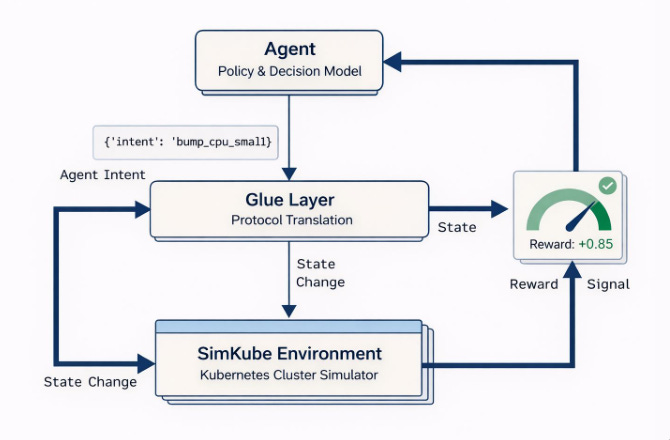
The first challenge that the team tackled was how to limit the scope of the project to something tractable in a 9-month period. There was a lot of excitement on the team about actually training an AI agent for Kubernetes, but this was very quickly ruled out as “too ambitious”, both from a “time” perspective and also from a “we’ve got no GPUs and no money to buy them” perspective. Instead, after a period of intense literature review and research/brainstorming, the team narrowed in on a much more tightly-scoped project: given an (extremely) small action space and a well-defined goal, can we build a set of APIs that someone else could use to train a Kubernetes agent on top of SimKube?
The team spent the bulk of the fall semester fleshing out this concept; the three main questions they needed to answer were “What are the inputs to the agent?”, “What does the agent output?”, and “How does the agent know it’s doing a good job?” To keep the project tractable, the team settled on the following answers:
The input to the agent—e.g., what it can observe about the Kubernetes cluster—is just “are the desired pods healthy?” and “what are the resource requests and replica counts for each pod?” This choice of inputs naturally restricted us to “autoscaling-like” behaviours, which not coincidentally, is also what SimKube is really good at!
Once the agent has collected its input and made a decision, it outputs a Simkube trace file. The modifications that the agent is allowed to make to the trace is extremely small; it can adjust pod replica counts and CPU/memory resource requests.
The agent has “succeeded” at its task when all of the pods in the cluster are healthy (aka, they have entered the “Running” phase at the end of the simulation).
This is obviously a hugely simplified version of the actual problem, but I think it was a great place to start: it was simple enough to reason about in a short period of time, but also complex enough that we were able to uncover some potential problems with the approach. And, it’s obviously extensible: if you want to make the problem harder, you can either expand the observation space, the action space, or the target metric.
By the end of the first semester, the team had implemented an extremely basic POC of the Kubernetes training arena based on SimKube that was able to stitch all of these pieces together. And we’d uncovered the biggest problem we would encounter along the way: time!
Time, time, time, see what’s become of me
It turns out that most reinforcement learning algorithms require hundreds of thousands of training iterations before you’re able to get something “good” out of them. But SimKube runs all of its simulations in real-time! That means if your trace file lasts for an hour, your simulation has to run for an hour5. This is.... kindof a problem. If you need 100,000 training epochs before your RL agent is able to effectively operate your Kubernetes cluster, you need to wait 100,000 hours, which is… 11 years. I’m sure in 11 years we’ll still be using Kubernetes, right? Also I hope you never need to re-train your agent.
Now, it turns out that there are some techniques in the RL community to deal with training against processes that run in real-time, and the most common one is just “run a bunch of training iterations in parallel”. So this is the approach the team took: they extended SimArena to operate in a distributed manner across multiple different machines. Every so often, the arena manager will checkpoint all of the running processes and synthesize the weights for the RL agent together. Along the way, the team got to learn all about the joys of AWS: spinning up EC2 instances, managing S3 buckets whose names are globally unique, and figuring out IAM roles. The clinic team also got to be the first users of ACRL’s SimKube AMIs, which was very exciting and validating.
So now we’ve solved the time problem: if you want your training run to take one day instead of 11 years, you just need 4200 EC2 instances! That shouldn’t be a problem for any of the big AI companies, I’m sure6.
Do you even lift, bro?
The final pieces of the project all came together within the last couple months; as the original goal of the project was to create an arena that anybody could plug their ML agent into, the team built two different hooks into SimArena.
The first was an interface based off OpenAI’s Gymnasium; if you’re unfamiliar (like I was), Gymnasium provides a standard interface for RL agents to interact with… well, just about anything. If you can make your system implement the Gymnasium API, then anybody who builds an RL agent can just plug it in and let it run. The second hook into SimArena that the team built was an MCP server for SimArena. MCP stands for “Model Context Protocol”7, and was an API developed by Anthropic8 for allowing LLMs to interact with arbitrary systems.
The last bit of work the team did was to train a very simple RL agent based on deep Q-learning, which is a standard RL learning algorithm used in a lot of different settings. I’m happy to report that not only did SimArena work, but the agent learned to make the Kubernetes pods healthy!
I’m extremely happy with the work that the team did this year, and really excited to see the results that they were able to put together; but don’t just take my word for it. The SimArena code is on GitHub, and you can also read the team’s final report for more details about their work.
And lastly, I’d just like to say that I’m really excited to have had the opportunity to work with these great students and to do another clinic project at HMC, it’s been an exceptionally valuable experience for me and (I hope) also for the people I’ve gotten to work with. A huge thank you to the team and the faculty and staff at Mudd that have made this so successful!
As always, thanks for reading.
~drmorr
Obviously this is the best game on the planet.
Why yes, this is the opening sentence to our research paper on the subject. I think this is an extremely novel insight that nobody else has ever had before.
TIL
Fun fact: when I was in grad school, the two subject areas I was considering pursuing were “scheduling and optimization” and “natural language processing/machine learning”. Obviously, I picked the one that was going to be lucrative in the long term. 🪦
Plus a bit of extra time needed to set up and tear down the simulation environment.
By the way, I’m willing to discuss licensing terms for SimArena to any of the big AI companies for the extremely generous pricing of “eleventy billion dollars”.
Not “Master Control Program”, although I think we can all agree that would be way funnier.
Just saying, SimKube is compatible with both APIs from the two major AI players in the space. We’re nothing if not forward-thinkers!
Congrats to ACRL and the team! Would you mind double checking on the link to the final report—I would love to read it!