

Using SimKube 1.0: Comparing Kubernetes Cluster Autoscaler and Karpenter

This post is part 2 of a 3-part series on some "real"1 results that I've gotten from my Kubernetes simulator project called SimKube. If you recall from last week, I also announced that SimKube has matured to v1.0.0, which is quite exciting! Of course this doesn't mean that SimKube is done, but it does mean that I think it can be useful, and I'd love to hear from you if you have used SimKube or you want to use SimKube for your work (also, SimKube now has a dedicated channel on the Kubernetes Slack instance). And lastly, as a brief recap, here's where we are in this blog series:
Part 2 (this post) - Running the Simulations
Part 3 - Analysis and Following up
I'd encourage you to go back and read last week's post for the most details, but as a refresher, here's where we're going: we want to produce some simulated results comparing the Kubernetes Cluster Autoscaler (KCA), with Karpenter, two popular competing projects in the Kubernetes cluster autoscaler space. To do this, we ran the "social network" app from the DeathStarBench microservice benchmark suite, and induced a bunch of load on the application to cause it to scale up. Last week, we observed that, on a single-node static Kubernetes cluster, the application quickly runs out of computing resources and falls over. We also observed that SimKube is actually a simulator, insofar as it replicates this same behaviour on a single-node simulated static Kubernetes cluster. This week, we're going to introduce autoscaling.
Three caveats before we get started: my purpose herein is not to say that KCA is better than/worse than Karpenter; my main goal is just to show off the types of analysis that SimKube can do. If there is any moral or lesson that can be learned from the actual results, it's that you should probably benchmark (or, dare I say, simulate) your own environment before making any decisions. The second caveat is that, while I am attempting to convey correct and useful information in this blog, it is not a scientific journal. There are a few mistakes I made when running these experiments, and a few things that I need to investigate further, before the results could reach a "scientifically meaningful" standard. But for the sake of "getting more information out there about SimKube", I've elected to punt on those extra results until later. The third caveat is that Substack isn’t a great platform for sharing this type of data; you can click on over to my not-so-secret mirror of this blog to see shiny interactive graphs and better tables.
Lastly, I'll note that all of the raw data for these experiments is publicly available for download here if you're interested in trying it out on your own!
What is real?
The first question to ask when you're running a simulation using SimKube is, "what should my simulated environment 'look' like?" If you have a production environment that you're trying to reason about, you probably want your simulation to look "close" to that production environment; in my case, I don't have a production environment, so I elected to simulate a relatively vanilla Kubernetes cluster running on AWS2. We're going to use the default Kubernetes configuration parameters, and we're going to have our autoscalers pretend to scale a set of common EC2 instances.
You may recall from my previous series on SimKube that I'm using Kubernetes-in-Docker (aka kind) to run the control plane for the simulation cluster3, and I'm using Kubernetes WithOut Kubelet (aka KWOK) to create a fake4 set of data nodes5. One nifty feature about KWOK is that the nodes it creates can be anything, as long as they're representable by the Kubernetes Node spec. So I wrote a quick script that scrapes the AWS EC2 API to get a (filtered) list of EC2 instance types which are then converted into a format that KWOK can consume.
The only question is, what types of instances should I choose from? This is actually a trickier question than you might think, as the choice is going to bias the results of the simulation in favor of one or the other autoscalers. See, KCA was originally designed under the assumption that Kubernetes clusters were (relatively) homogeneous, in other words, all of the compute nodes in the cluster "look" more-or-less the same. Why is this important? Well, if you have some nodes in your cluster that have 4GB of RAM, and other nodes in your cluster that have 32GB of RAM, and you try to launch a pod that requests 10GB of RAM, only one of your node types is going to actually satisfy that demand.
So, the way that cluster autoscaler works is that it registers in advance6 the node types that you want to make available in your cluster, and when new pods come in, the autoscaler will iterate over all the possible "registered" node types to find the "best" one. In pseudocode, the process looks like this:
def scaling_loop():
while true:
refresh_cluster_state()
new_nodes = scale_up()
if new_nodes.empty():
try_scale_down()
def scale_up():
node_types := []
for each unschedulable pod:
for each registered node_type:
if pod fits on node:
score(node_type)
node_types.append(best_scoring_node)
return node_types
def try_scale_down():
...
I am eliding a bunch of details here: the real logic is quite a bit more complex. For example, if we've already chosen a node type for unschedulable pod A, and unschedulable pod B will also fit on that node type even after pod A is scheduled there, we don't (necessarily) want to launch a new node for pod B. But the main point is, every time we go through the scaling loop, it manually iterates through all the different node types that are available—and since this manual iteration involves making a whole bunch of AWS API calls, it's relatively slow if you have, say, 1000 different node types7.
On the flip side, Karpenter was designed by AWS to take advantage of the entire set of EC2 offerings by default; unlike with KCA, where users need to "opt in" to particular instance types or classes, Karpenter instead uses an opt-out mechanism where you filter down from "everything". This is exciting for users, because Karpenter knows a lot more about the ecosystem in which it operates, and can make better choices based on that information; and it's a lot more efficient at handling a large set of instance types because it was designed that way from the ground up.
But, you can probably see where this is going: in my simulation comparison, if I limit the number of EC2 instances that are available for the autoscalers to use, then I'm not really showcasing one of Karpenter's most exciting features, but if I open up the entire set of AWS EC2 instances for scaling, then KCA is going to fall over.
In the end, I elected for (what I hope is) a reasonable middle ground: I picked a subset of "common" EC2 instances that are probably in wide use at a lot of different organizations to use for both autoscalers. That list of instances is8:
c6i.4xlarge+ /c7i.4xlarge+c6a.4xlarge+ /c7a.4xlarge+m6i.4xlarge+ /m7i.4xlarge+m6a.4xlarge+ /m7a.4xlarge+r6i.4xlarge+ /r7i.4xlarge+r6a.4xlarge+ /r7a.4xlarge+
If you're not familiar with AWS EC2 instance names, the c/m/r letters at the beginning of each indicate the "compute class": c means "compute optimized", and have a 2:1 memory:vCPU ratio; m means "general purpose" and have a 4:1 memory:vCPU ratio, and r means "memory optimized", and have an 8:1 memory:vCPU ratio. The 6/7 indicates the compute generation, where 7 is the current generation (at time of writing), and 6 is the previous generation. The i/a indicates whether it's running on Intel or AMD hardware, and the designation following the dot indicates the size, that is, the number of vCPUs on the instance. So, in common words, for this simulation, I'm allowing the autoscalers to pick from compute-optimized, memory-optimized, or standard instance types, using either Intel or AMD hardware, of either the current or the previous generation, with at least 16 vCPUs on each node. Even though this is a reduced list of instances, it is a quite broad selection: there are still 102 different instance types to choose from!
Enough talky, let's see some results
So now that we understand the environment we're simulating, let's look at some graphs! These first two graphs show the "running" and "pending" pods counts for both KCA and Karpenter:


As you can see, unlike last time, all our pods are getting scheduled! There are a few brief spikes of pods in the "Pending" state, but both autoscalers respond quickly and the pods get scheduled. This is great! We've shown that we can prevent production outages by introducing an autoscaler into our cluster! But let's see what kinds of nodes are getting launched by each autoscaler:


Here's where we see our first significant difference between KCA and Karpenter: you'll observe that Karpenter is extremely consistent about the choices that it makes in every simulation, whereas KCA is not. This is unsurprising: out of the box, KCA evaluates the list of feasible instance types, and if there are multiple "equivalent" instance types, it will pick one at random. This behaviour is probably not what you actually want, and of course it is configurable, but here we see a (potential) advantage of Karpenter: out-of-the-box, it has some consistent default behaviour9.
Of course, the choices that each autoscaler makes is only one possible axis of comparison. We might also be interested in how quickly each autoscaler makes those decision, or how many compute resources they take. If Karpenter makes better decisions, but it takes 10x as long to make them, it might not be worth it. Unfortunately, the DSB trace that we have is too small to really reason about the autoscaler performance. We're gonna need a bigger boat.
What if we multiplied by 100?
You might think, based on everything you've read so far, that in order to evaluate autoscaler performance at a larger scale, we'd need to re-run our "production" system at a larger scale and collect another trace. This would be somewhat challenging (or at least, very expensive: I certainly don't have the money to run a thousand-node compute cluster for any significant period of time). But, here's one of the things I'm reallllllly excited about for SimKube: once you have a trace file, you can use that trace to generate new traces10. And we have a trace file!
So here's what I did: I took the previous trace file, multiplied all of the replica counts for each deployment by a constant factor, and changed the resource requirements to slightly more "realistic" numbers11. Essentially, I took the entire trace and scaled it up by two orders of magnitude. Now we should be able to see some performance differences between the autoscalers. Let's take a look12!
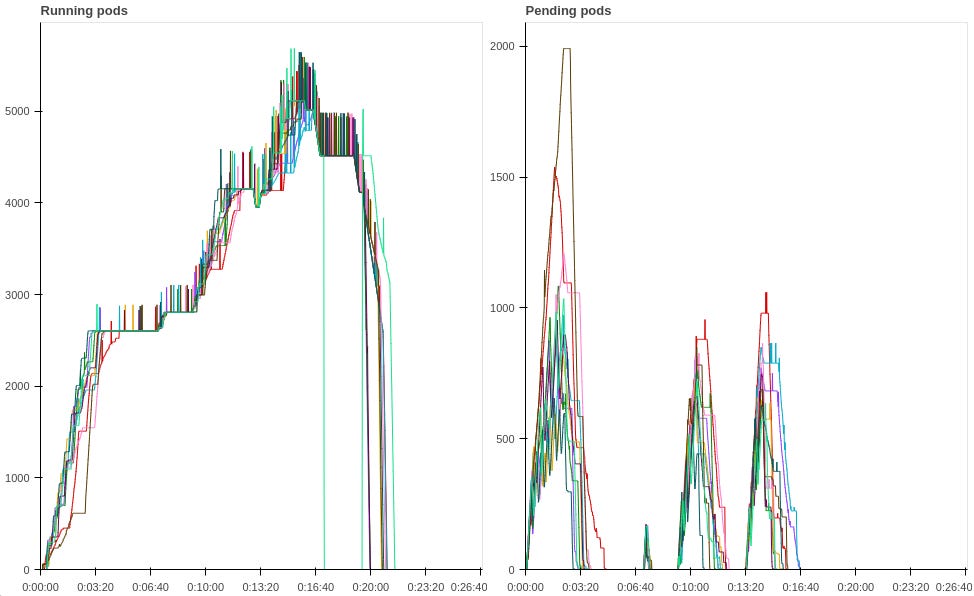

We can see here that it takes significantly longer for the application to reach a "steady state" after each scaling activity, but we can also observe that Karpenter is able to get pods out of the "Pending" state a lot faster than KCA. Whenever there is scaling activity, KCA has (on average) 1000 pending pods hanging around for a significant period of time, whereas Karpenter only has a quarter of that! These results show off another of Karpenter's big advantages over KCA: it essentially has two different control loops, a "fast" loop and a "slow" loop. The fast loop just gets pending pods scheduled as quickly as possible; the slow loop will then go back through and shuffle things around to get a more "optimal" solution. KCA, on the other hand, just has a single, relatively slow control loop, which means that it takes a lot longer for it to initiate scaling actions and get pods out of the pending state. In fact, we can graph this data for both autoscalers:


In the first series of graphs, we can see that the KCA main loop is taking somewhere between 20 and 60 seconds to run whenever it needs to scale up. And you can also see that the majority of that time is dominated by the scaleUp subroutine; scaling down doesn't take that long, which makes sense for this simulation because there isn't that much downscaling activity that can occur.
On the other hand, Karpenter's provisioner controller (the controller that's responsible for creating new nodes when pending pods are observed, aka the "fast" loop) takes a maximum of around 12 seconds, and is sometimes significantly faster than that. The disruption controller (the controller that's responsible for consolidating the cluster and downscaling, aka the "slow" loop) takes significantly longer, around 15 seconds on average and sometimes as much as 30 seconds. In either case, this is quite a bit faster than KCA!
Let's also look at the instance type selections for each autoscaler—actually, you know what, I'm not going to put the tables in here, they're pretty cumbersome to read. But you can download my Jupyter notebooks or the raw data to look at them yourself if you want. What we observe is consistent with the previous (small) DSB simulation: namely that KCA is picking instance types at random, which sometimes results in really good behaviour and sometimes results in really bad behaviour. Karpenter demonstrates a bit more variability in this experiment than in the previous one; while it predominantly uses m6a.48xlarge and c6a.48xlarge instance types in every simulation, it has a smattering of smaller instance types that it chooses from that differ between each simulated run.
Lastly, let's take a look at the resource utilization for KCA and Karpenter in our simulations13:


From these graphs, we can see that while both KCA and Karpenter are using similar amounts of memory, KCA is using 2-3 vCPUs during its busy scale-up periods, whereas Karpenter is using more like 1-2 vCPUs. What's going on here?
I have not yet confirmed this hypothesis, but I believe that what is happening results from another difference in implementation between KCA and Karpenter: see, KCA actually imports the real Kubernetes scheduler code, and runs a simulation14 of the scheduler on every scale-up loop for each possible instance type it's considering. The Kubernetes scheduler code is itself pretty hefty, which means that KCA is doing a lot of work to identify valid candidates. While Karpenter still does a scheduling simulation on scale-up, it is not15 importing the whole Kubernetes scheduling codebase; instead, it is making some approximations that enable it to run significantly faster (and with significantly fewer resources), but may not handle all scaling scenarios. So, if you're running workloads that need to scale correctly in an area that Karpenter doesn't work well with… well, you might need to use Cluster Autoscaler instead.
Wrapping up
This post definitely wins in the "most graphs I've ever posted" category. If you've made it this far, thanks for sticking with it! I want to re-iterate: this set of blog posts should not be taken as "Karpenter is better than KCA" advice (or vice versa). It's not even strictly speaking a great scientific experiment (as I discovered after the fact, see also footnote #8). My broader point is, there are real tradeoffs that come with either autoscaling solution, and before you pick one over the other, you should maybe run some simulations in your environment to see how they perform.
I've got one more post in this series: next week, I'm going to look at the performance of SimKube itself, and see what we can learn and how we can improve it in the future.
As always, thanks for reading!
~drmorr
And by "real" I mean, "well, it could be real…
If you recall from last week, Karpenter only works with AWS and Azure right now, and I have more experience with AWS offerings, so this was a natural choice for me.
And if you want to go even further down the rabbit hole, kind itself uses kubeadm to configure the control plane nodes.
Ahem, "simulated".
If you're paying close attention, you'll notice that this isn't quite accurate: KWOK is not going to be the thing scaling the cluster up and down, it's just responding to the node objects that get created in etcd; it's actually the autoscaler that's the thing creating node objects. Fortunately, both Cluster Autoscaler and Karpenter have "cloud providers" that know how to talk to KWOK already. So I just needed to tweak the output from my script to generate a list of instances for either the KCA or Karpenter cloud provider, depending on which one I was testing at the time.
There is also a mode where KCA can discover or self-register node types from your AWS account, but this still has some of the same fundamental issues.
This might seem like a lot until you realize that implicit in the phrase "node type" is not only node characteristics—e.g., CPUs, memory, etc.—but also placement—e.g., what availability zone the node runs in. The latter is very important if you're using pod topology spread constraints, which is very often enabled for reliability reasons. If you're also juggling spot vs on-demand instance types, you can easily end up with 1000 different node groups in your cluster.
Actually this isn't quite accurate; I discovered as I was doing this data analysis that KCA included smaller instance types in its set of possible choices, which could skew the results even further from being "fair" towards KCA. The comments I'm going to make in this blog post are still (I believe) directionally correct, but I would need to re-run the experiments before, for example, reporting these in a formal scientific venue. I hope it's clear by now that this blog is not a formal scientific venue.
Whether this default behaviour is "good" is of course application-dependent, and isn't something I can comment on in this blog post. You might need to run some simulations in your own clusters to find out! hint hint
See also: Exploring the Kubernetes Graph.
Remember in the last blog post how I set every pod to request 1 vCPU and 1GB of RAM? And how I said that I'd regret that decision? It turns out that using these values makes the autoscaler's job a little too easy: every pod fits nicely on every type of EC2 instance, regardless of what else is scheduled there. By changing the resource requests for every service, I made the autoscaler's binpacking job harder.
You will notice in the following graphs some weird spiky behaviour in the Cluster Autoscaler graphs. I am about 85% sure this can be chalked up to the host (and therefore, the metrics pipeline) being significantly more overloaded for the KCA simulation than for the Karpenter simulation. I need to do a follow-up experiment to definitively confirm this theory, though.
Again, notice there is wonkiness in the metrics data for cluster autoscaler, particularly in the memory graph; as before, I believe this is due to how overloaded the metrics pipeline is getting, but I need to re-run the experiments to know for sure.
Yo dawg, I heard you like simulations, etc etc.
At least, the last time I checked.