

HOWTO: Use SimKube for Cost Forecasting

Recently, I’ve had a number of folks ask for some more details about how SimKube can be used to predict or forecast your Kubernetes expenditures, and I realized that I’ve said you can do this several times, but I’ve never actually gone through the details! So this post will show you how.
Problem statement: how much will we save by doing X?
Anyone who’s worked on a platform team has probably at some point had their boss ask them “our platform is expensive, how can we make it less expensive?” When you’re dealing with Kubernetes and the cloud, there are a lot of variables at play, and it can be really tough to know in advance which knobs and levers are worth tuning. That’s where simulation comes in! If you can spend a couple hours running a simulation to see some projected savings, using real production data, that could potentially save you a lot of time and wasted effort. We’ll see why in just a minute.
First, some background on the specific scenario I’m demonstrating today: in recent years, the big cloud providers have started offering ARM-based compute resources with similar-or-better performance characteristics to their equivalent x86 machines, for a slightly-reduced rate1. The details of the different architectures aren’t super important for this post: all you need to know is that they aren’t compatible, so it may involve recompiling a lot of code as well as figuring out how to serve multi-platform Docker images. All of this is doable, and in fact quite a few of the big tech companies have done it, but the key point is that it’s a non-trivial amount of engineering effort to enable. So the natural question you might ask is, “Is the savings worth the effort, and over what time horizon?” And that’s the question we’re going to tackle today in this post.
The problem setup is straightforward: I’m going to use the same DeathStarBench trace data that I used in my comparison of KCA to Karpenter; I’m using the latest version of Karpenter for autoscaling, and I’ve configured SimKube to “look like” AWS by offering the full suite of AWS EC2 instances for scaling.
We’re going to run three different simulations: the first is using only x86 machines (as in my KCA vs Karpenter comparison, we’re using m, c, and r class nodes of 6th and 7th generation). In the second simulation, I have configured a few of the deployments in the trace to be “ARM-compatible”, and added in the equivalent Graviton nodes into the mix; and in the last simulation, I only run on Graviton nodes.
Why did I set things up this way? Well, in any large Kubernetes deployment, you probably have some workloads that don’t care about the underlying architecture: Python code, for example, is generally architecture agnostic2. It’s a high-enough level language that the architecture details are abstracted away and it should “just work”. Golang is a step up on the difficulty ladder: you will need to recompile your code, but Go offers very good cross-compilation support, so it’s probably not “too hard”. Java code is probably similar to Golang in this regard. Highest on the complexity ladder are things like C/C++/Rust: especially if they have a lot of low-level system requirements, it’s probably going to be a lot of work to port from x86 to ARM.
So, this simulation is answering the question, “How much will we save if we just port the easy stuff to ARM?” compared to “How much could we hypothetically save if we ported everything to ARM?” Since this is all made-up for illustrative purposes, I just picked a few DeathStarBench deployments at random to be the “easy stuff”, but you can hopefully see how this mirrors the types of conversations that occur in many organizations.
Here’s the cool thing: because all my workloads are fake, they don’t actually care about the underlying architecture. In fact, the nodes are fake too, so they can report whatever architecture I want3. If you were to do this experiment using real nodes and real hardware, it would probably take you a few weeks to even just get things to the point where you could run a test; and I did the same work in an afternoon.
The results: is the work worth it?
Now that we understand the problem statement, we’ll look at the results. First, we need to establish our baseline: how much does it cost if nothing uses Graviton?
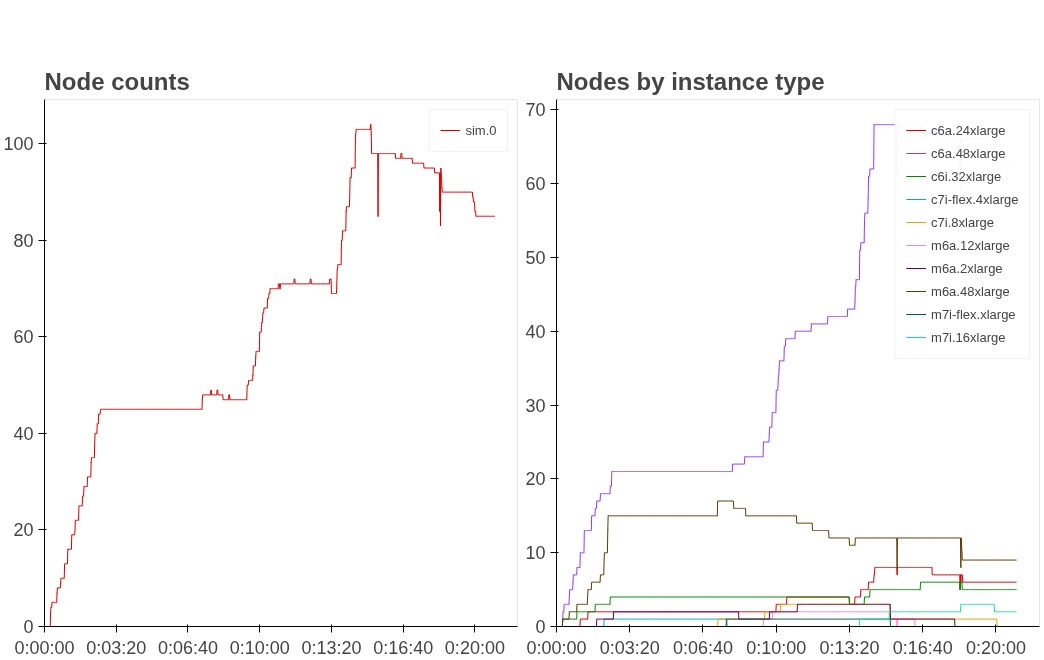
Figure 1 shows both the total node count as well as the node composition in this experiment. You can see that predominantly, we are using c6a.48xlarge instances, which Karpenter has presumably chosen because they’re one of the cheapest instance types that supports the large number of pods that we’re running. We can multiply this set of instance type data with the publicly-available on-demand pricing for each of these instance types to find out how much everything costs. Doing so, we end up with a total price of $149.22 for this twenty-minute slice of time4.
So what happens if we port the easy stuff over to ARM? I looked at the five largest (in terms of pod count) deployments in the simulated trace file and allowed them to run on Graviton nodes5; everything else was restricted to x86. Re-running the experiment yields the following:
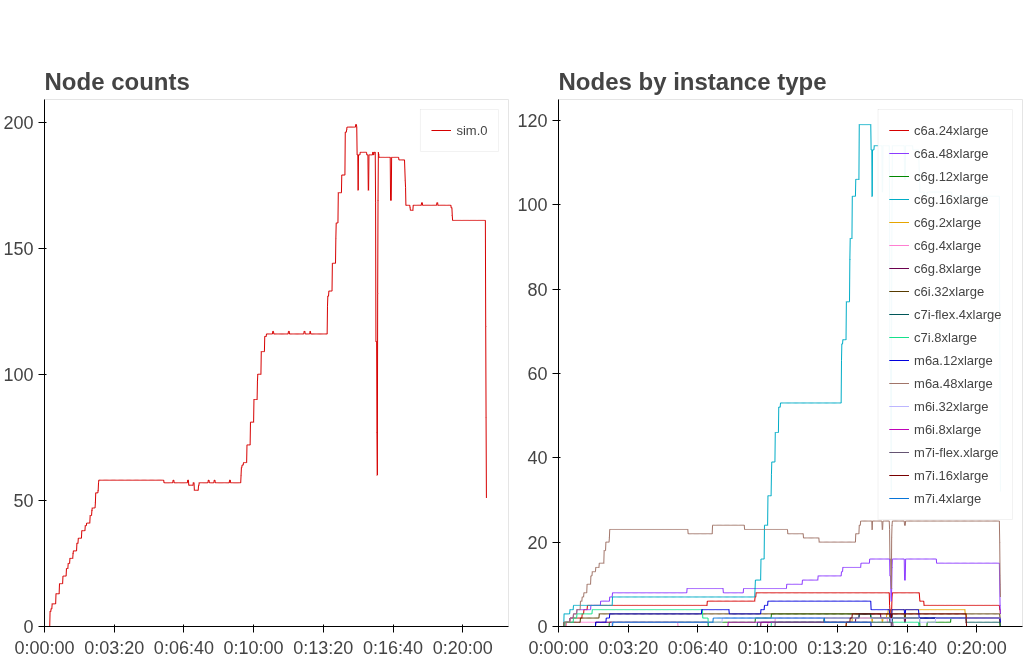
You can see in Figure 2 that we are definitely using Graviton nodes now6! We’re running a lot more (but smaller) nodes, and the most common instance type is the c6g.16xlarge. That seems promising, how much did it cost? We run the numbers and find out that it costs… $150.72. Basically the same as before7! Sure glad we didn’t put in all that engineering effort to save $08.
So OK, doing just the easy stuff doesn’t help in this case, and we clearly don’t have the time to migrate everything to Graviton right now9, but just hypothetically speaking, what happens if we were able to wave a magic wand and move everything over to Graviton? Figure 3 shows the answer:
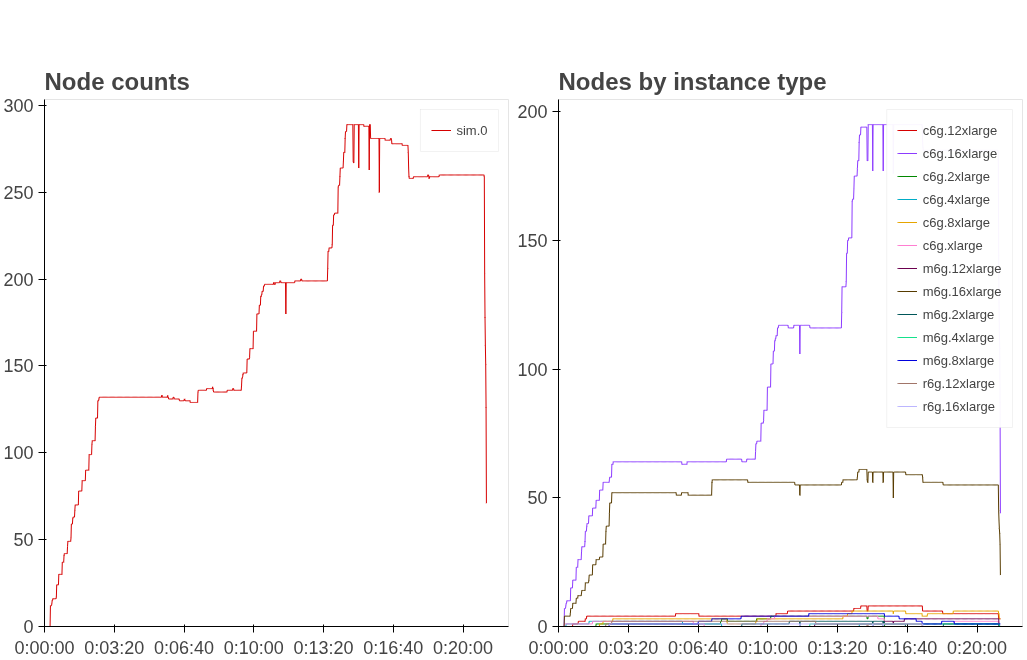
Now everything is running on Graviton, and our total EC2 spend is predicted to be $138.24 for this 20-minute time slice. Now we’re talking! There’s that 10% discount showing up finally10. Is that really worth the 6-12 months of concerted engineering time it would take to port all these workloads over to support ARM? I mean, maybe, maybe not, we’ve now moved from the realm of engineering into policy and priority decisions—but the point is, you can make better decisions now because you spent a few hours running some simulations and collecting data first.
A cool epilogue: SimKube plus KubeCost
Even though this was kindof a “toy” example, hopefully this is helpful to see how you might be able to use SimKube to make decisions around all the different cost levers that are available in Kubernetes and the cloud. I wanted to close with one cool observation: if you were going to repeat this for your own workloads, you could do what I did, and collect all the data, and then multiply it out by hand. It’s not hard to do. BUT, there are also existing tools out there to help you track your Kubernetes spend that make it a lot easier! Possibly one of the more well-known ones is KubeCost, which was recently acquired by IBM. KubeCost integrates with all the different cloud providers and can pull pricing data from the public APIs, as well as take into account EBS volume usage and any of your negotiated volume discounts or other cost-impacting factors: and you can just, you know, install KubeCost into your simulated environment and get some costs out! Here’s a screenshot of me doing exactly that:
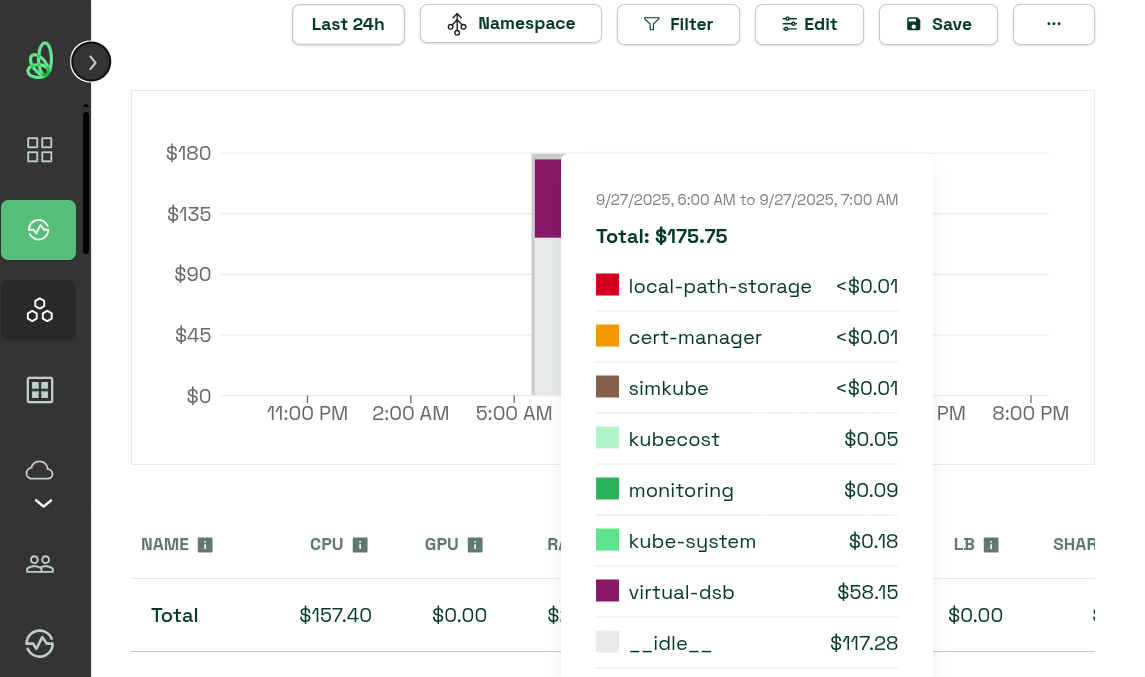
I dunno, I think this is pretty nifty, and it really shows how you can start to use all of your existing tools and components in your simulation environment as well, to take your simulation analysis and data collection to the next level.
Anyways, I hope this was an interesting read for you all, and that it gives you some ideas for how you can use SimKube in the future! As always, thanks for reading!
~drmorr
AWS was the first (I believe) to start manufacturing their own ARM chips, called Graviton, for use in their public cloud offerings; although, famously, Apply abandoned Intel architectures several years ago and now exclusively sell ARM-based computers in their M* lineup.
The exception being, of course, if you rely on any compiled Python libraries: pandas, numpy, scipy, for example.
They could even report some magical, mystical new architecture that hasn’t even been invented yet if I wanted. You could call it, I dunno, just spitballing, ACRL64.
Note that for this simulation, I’m ignoring everything but the EC2 instance cost. There’s a whole lot of other things that go into an AWS bill—EBS volumes, network costs, ECR costs, and more. If we wanted to we could factor those into our simulation as well, but it would be more effort. Still, it would probably be less effort than porting everything over to Graviton and trying it out for real.
The way I did this was to create a separate Karpenter node pool with only Graviton instance types, and added a taint to them so that only pods that tolerated the different architecture could be scheduled there
The big inverse spike at the 15 minute mark is just a metrics artifact, Prometheus got overloaded and dropped a bunch of metrics on the floor, it happens, life goes on.
If you were doing this simulation for real, you’d probably want to repeat the experiment several times to smooth out any noise or non-determinism in the results, but for the purposes of this post you get the idea.
You might also ask the question of why we got this result; shouldn’t Karpenter show some savings, even if it’s not very much? We’d have to really dig into the results here to understand what’s going on, but my initial hypothesis is that we’ve essentially hamstrung Karpenter’s ability to consolidate nodes. Some stuff really wants to run on Graviton because it’s cheap, but not everything can, so I’m guessing Karpenter’s consolidation routine is getting stuck; combine this with the fact that more (but smaller) instance types leads to worse bin-packing in general, and I’m guessing this is why we don’t actually see any savings here.
After all, we’ve got OKRs to half-ass!
OK, OK, it’s only 8%. Sue me.